
Github
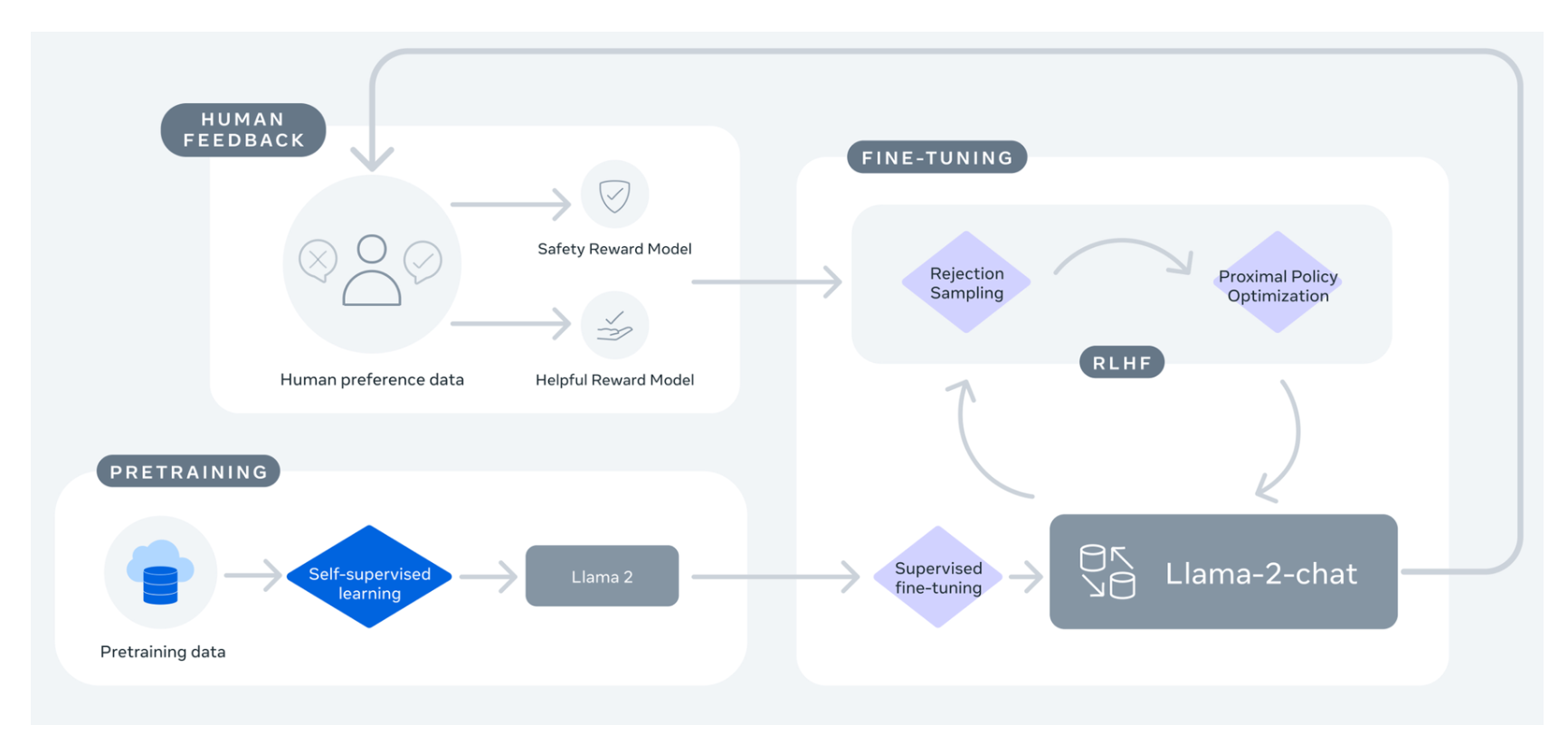
This release includes model weights and starting code for pretrained and fine-tuned Llama language models ranging from 7B to 70B parameters This repository is intended as a minimal. Llama 2 is a family of state-of-the-art open-access large language models released by Meta today and were excited to fully support the launch with comprehensive integration in Hugging. The llama-recipes repository is a companion to the Llama 2 model The goal of this repository is to provide examples to quickly get started with fine-tuning for domain adaptation and how. The LLaMA 2 model incorporates a variation of the concept of Multi-Query Attention MQA proposed by Shazeer 2019 a refinement of the Multi-Head Attention MHA algorithm. Llama 2 is a collection of pretrained and fine-tuned generative text models To learn more about Llama 2 review the Llama 2 model card What Is The Structure Of Llama 2..
In this work we develop and release Llama 2 a collection of pretrained and fine-tuned large language models LLMs ranging in scale. Result We have a broad range of supporters around the world who believe in our open approach to todays AI companies that have given early feedback and are. Result Technical specifications Llama 2 was pretrained on publicly available online data sources The fine-tuned model Llama Chat leverages publicly available. Result In this work we develop and release Llama 2 a collection of pretrained and fine-tuned large language models LLMs ranging in scale from 7. Result model card research paper I keep getting a CUDA out of memory error How good is the model assuming the fine-tuned one for handling direct customer input..
Https Github Com Microsoft Llama 2 Onnx Blob Main Model Card Meta Llama 2 Md
GPT-4 and LLaMa 2 offer stark contrasts in terms of their ecosystems and tooling LLaMa 2 introduced as a cutting-edge open-access language model is now seamlessly integrated into the popular. GPT-4 LLaMA 2 Mistral 7B ChatGPT and More The top large language models along with recommendations for when to use each based upon needs like API. A bigger size of the model isnt always an advantage Sometimes its precisely the opposite and thats the case here As Llama 2 is much smaller than. Key Differences based on 9 Parameters OpenAI has not officially disclosed the exact parameter count for GPT-4 but estimates suggest it. In July 2023 Meta took a bold stance in the generative AI space by open-sourcing its large language model LLM Llama 2 making it available free of charge for research and commercial use..
WEB Understanding Llama 2 and Model Fine-Tuning Llama 2 is a collection of second-generation open-source LLMs from Meta that comes with a. In this notebook and tutorial we will fine-tune Metas Llama 2 7B Watch the accompanying video walk-through but for Mistral here. WEB torchrun --nnodes 1 --nproc_per_node 4 llama_finetuningpy --enable_fsdp --use_peft --peft_method lora --model_name. WEB In this section we look at the tools available in the Hugging Face ecosystem to efficiently train Llama 2 on simple hardware and show how to fine. WEB In this work we develop and release Llama 2 a collection of pretrained and fine-tuned large language models LLMs ranging in scale from 7 billion to 70..



Komentar